💭 foundational concepts for developing regenerative information ecologies & empowering knowledge commons
draft:
inb4: this article could be multiple articles, which could greatly help the reader by breaking down the subjects into simpler parts. however, that's not my objective.
my goal with this piece is to present multiple references and perspectives on the same “information design/management” space (which is a huge field), in a way that is both bringing something new to the discussion and challenging us to hold all of this complexity in a state of 5-body awareness.
i.e. it's not about intelectually understanding the contents of this article, but "getting it" in all of our 5 bodies - physically, emotionally, intellectually, energetically, archetypically.
it can take multiple readings, reflecting and referring back to this over a long period of time. that's expected. just like it took me years to consolidate it.
i'll be adapting this into simpler, smaller pieces of content and posting them on social media as well, but this is the place where i'll dive as deep into it as i can, and where you can refer back to.
if you’re interested in further simplifying this and/or transforming into visual forms, especially maps/boards, let me know! i already have some sketches and would love to collaborate.
context:
i’ve been very involved with two online movements/communities (metacrisis & knowledge management) for about 5 and 9 years, respectively. this article is a compilation of the best concepts/resources i’ve gathered from them — and from outside of them, but that are relevant to what they’re about.
whether you’re familiar with these communities/terms or not, my goal is to bring new, powerful perspectives as to how we can address some of the major crises we’re living through: the crises of imagination, meaning, agency and connection — which i argue are all sustained by downward spiraling feedback loops between our degraded information ecology, adversarial economic system, [unloving] coordination mechanisms and siloed data structures/knowledge management tools.
assumed audience: you’re familiar with domains/terms such as regeneration, self-development and the online media landscape, or at least you can infer how/why they’re relevant to our lives. you care about transforming yourself and making society a better place.
before i jumping into the main subjects of this article — information ecology and knowledge commons — i want to share with you a bit about my background, worldview and where i'm oriented towards, so you know some of my biases and where this research is coming from.
hopefully this can support you to do your own sensemaking on the subjects i'm sharing here.
the missions i’m committed to working towards are:
- transforming life into a game. building/curating/integrating systems, tools and practices for playing life in more shared, collaborative, regenerative and disruptive ways.
- creating glocal systems that are antifragile and regenerative by design, empowering and supporting all human beings, as well as raising their level of responsibility with respect and collaboration with all other forms of life.
- enabling conscious lifestyles that are shared, collaborative, fun, regenerative and disruptive by design. promoting greater awareness, freedom, empowerment, adventure/fun, healing and contribution.
i share this as a way to clarify the “agenda” behind this article (the biases/direction of the writer), and as means to find others who are on similar journeys and wish to collaborate towards these desired futures.
these 3 themes of work came both from my research on systemic challenges, game theory and existential risk, as well as personal intuitions, insights and awakenings i had on my self-knowledge path.
throughout this path, i’ve found many organizations, communities and people doing amazing work. a few of the ones that impacted me the most being: daniel schmachtenberger, ken wilber, maggie appleton, [metagame], SEEDS, possibility management, [protocol labs], holochain, [subconscious], L1F3.STREAM, [high stakes academy] and mundos possíveis (the last three only have content in brazilian portuguese for now).
so much so that to varying degrees, i contribute or contributed to each of these projects for some time. i’ll still write about why i believe each of them is relevant, what they bring of uniquely valuable to the world, along with lots of other references of people/organizations doing similar/complimentary work.
in short, each of these are working on different very important systemic needs of our civilization. from upgrading human thoughtware and conducting authentic adulthood/psycho-spiritual initiations, to building systems for enabling glocal economies that are regenerative by design, giving people agency and ownership over their own data and technologies, visualizing themselves and every aspect of their lives and evolutionary journeys through data, and finding content, communities and experiences that expand, connect and propel us to grow.
after covering as much ground as i could in answering the question — “who’s building the next systems, tools and communities for an open, collaborative, regenerative civilization?”, my intent in this article is to talk about what still remains/stands out as open questions and challenges for me.
i don’t think we’ve yet found comprehensive solutions to these challenges, but i do see a few possible nourishing paths forward. i’ll share the most impactful perspectives, concepts, tools and organizations i found, but i also wanted to acknowledge that.
this means many things. it can be great! lots of fun journeys to go on. at the same time that we can pay attention and notice that there are people (ourselves included) gravely suffering because we’ve inherited systems that go against the evolution and full expression of our beings.
i’m not advocating for “finding all of the answers and designing one-fits-all dystopian control systems”. what i’m saying is that i believe that if we map the problem/landscape as closely as we can to reality, it can help us steer our efforts towards creating more beautiful futures together. and there are lots of covered territory already.
therefore, the “unsolved” challenges i’m talking about are:
- healing and transforming our information ecology
- enabling a vocational economy
i’ll focus on the information ecology part on this article. the next one will be on the vocational economy, breaking down the 4 best approaches i’ve found so far — SEEDS, L1F3.STREAM, metacurrency and metagame.
as you might have guessed so far, i’ll strive for understandability in this article, so my definitions will be mostly loose and free from academic jargon.
defining regenerative information ecologies & empowering knowledge commons
daniel schmachtenberger was the first person i found referring to the information ecology in this way and bringing profoundly useful distinctions on a few podcasts, but he really got the word out on rebel wisdom’s “war on sensemaking” series (highly recommend the first episode), in august 2019, and afterwards, when he went on joe rogan’s podcast with tristan harris (a big name, founder of the center for humane technology).
alongside him, a largely unknown, yet somewhat influential group (mostly) made of integral thinkers, philosophers, transpersonal psychologists and spiritual practitioners, started self-organizing and sharing information / earnestly trying to making sense of the value and belief systems of online communities, aiming to move beyond polarization (left-right spectrums) and towards integration of their perspectives.
this online “sensemaking” scene was mostly sparked by the culture wars triggered by jordan peterson’s rise in popularity back in 2018 and the confrontations between individuals such as him, sam harris, eric weinstein, joe rogan and others with the mainstream media.
(the stoa’s 2018 article “memetic tribes of culture war 2.0” being one of the cornerstone pieces of content at the time)
since then, the stoa has been an online community giving space/voice to many interesting people and initiatives. a few of the ones i connected with the most were: john verveake’s work, phoenix culture, fourgames, ontological design, roote, flow genome project, the society library, wardley mapping, golden and startupy (soon rebranding to sublime) — these last three not present on the stoa, but nonetheless relevant in this context of regenerating the information ecology.
(you can find many other resources talking about/addressing the challenges of what this community described as “the metacrisis” on directories such as this one)
as some of these ideas have been informative to many researchers, web3 builders, social activists, spiritual practitioners and regenerative systems designers (myself included), i believe there are many concepts that deserve to get outside this bubble and more into the mainstream conversation of how to build a better internet.
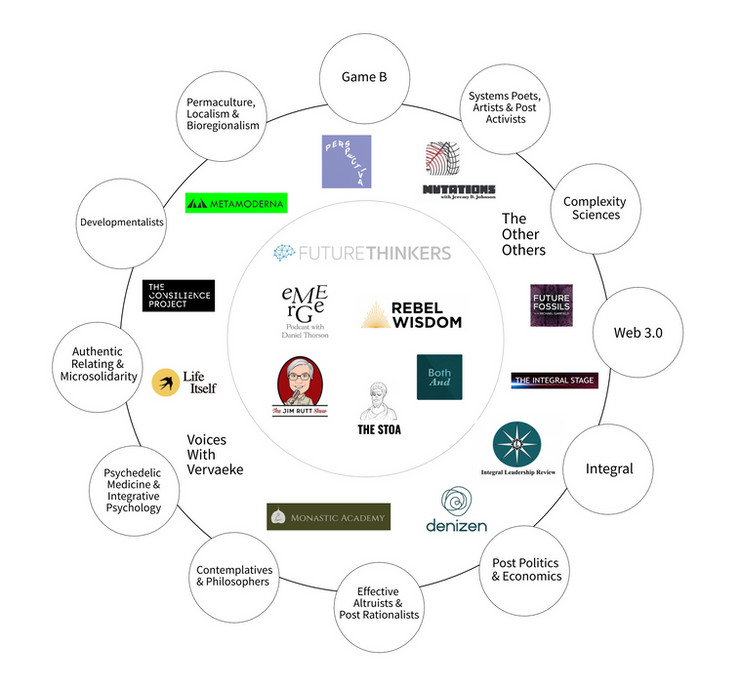
(see life itself’s metamodern ecosystem map for an overview on communities inspired/informed by this knowledge, or joe lightfoot’s 2021 “the liminal web” article, referenced by the map right below)

an overview of the topics and communities related to this ecosystem — joe lightfoot, 2021
so, onto the definitions:
- developing regenerative information ecologies starts with recognizing that nature’s principles also permeate our informational ecosystems and therefore, committing to stopping degenerative/extractive/adversarial patterns and creating new forms of sharing information that are regenerative for all of the participants in the ecosystem.
it’s important to notice that our informational systems are deeply entagled with our economic systems, which also has such extractivist design. so just “wanting to depollute the information ecology” won’t work as long as the incentives for pollution are still there.
nonetheless, we can start building regenerative habits around information production/consumption and systems that are regenerative by design, while we also transform our economic systems.
- empowering knowledge commons means that the common structures we have for building and sharing knowledge are oriented towards empowering the individual, not keeping them dependent.
applying this to our current knowledge common systems (social media [which isn’t actually a commons, but unfortunately in many cases still acts as such], libraries, public information curation portals, public data repositories) also means reducing information overwhelm, misinformation, propaganda and increasing their quality, accessibility, discoverability and relevance.
much of the web is public, but that doesn’t mean its content is any “good”, “true” or accessible.
accessibility if really considered more deeply, implies different levels of depth and formats for people (and agents) with different levels of previous knowledge, time available and mental/emotional availability.
educators and platforms such as wikipedia, edx, khan academy, crash course, veritasium, etc, have been creating “knowledge commons” for a long time.
but this knowledge is mostly academic, and many times not directly applicable to one’s life.
in contrast to this, wikihow and many youtube channels exist to share guidance on multiple practical aspects of life.
yet knowledge about navigating the complexity of our online world is pushed to/concentrated in either:
a) boring corporate/online marketing/communication agencies,
b) elitist business intelligence/trends/futures observatories, or
c) niche subcultures/communities no one’s heard of
which leads us to the first foundational concept:
1) digital cartography (a.k.a. mapping)
this is one of the, if not the most underrated field of study that i know of.
it seems that we’ve relegated this to hobbyists, artists and intelligence agencies. even them (no offense intended) are really bad/primitive.
since “all of humanity’s knowledge is now available at your fingertips”, i imagined we’d have found good ways to organize and share this knowledge. after all, it’s been over 20 years since the internet has become widespread in western civilizations.
yet what we got was addictive, attention-hoarding platforms and mechanisms that profit out of this big data through opaque algorithms and thrive off of our unconscious biases and instincts.
of course, there’s been initiatives such as libraries and encyclopedias for thousands of years and some digital equivalents (wikipedia, arxiv, internet archive, wolfram alpha, open knowledge maps and some more anarchist-leaning solutions, such as the former thepiratebay, torrents and present-day library genesis, plus several others i’ll introduce throughout the article), but our “maps of the internet” and “knowledge maps” in general remain terrible.
you might ask yourself why that’s relevant in the first place.
in short, besides helping you organize knowledge/information, maps can give you glimpses of what you don't know that you don't know.
but the best explanation i found as to how this subject (of mapping and topographical intelligence) can be so crucial, plus what it allows us to do that would be otherwise extremely difficult or straight up impossible, comes from simon wardley, on the first chapter of his book introducing wardley mapping.
(i highly recommended reading it, it’s available as an article on medium, only 28 minutes long and one of the most densely packed with insights things i’ve ever read)
he proposes a thought experiment that’s so illustrative that i’ll quote it directly here:
“I want you to now imagine you live in a world where everyone plays chess and how well you play the game determines your success and your ranking in this world. However, in this world, no one has ever seen a chessboard. In fact, all you’ve ever seen are the following characters on a screen and you play the game by simply pressing a character, your opponent counters and then you counter and so forth. The list of moves being recorded underneath the characters.
Figure 4 — Chess World
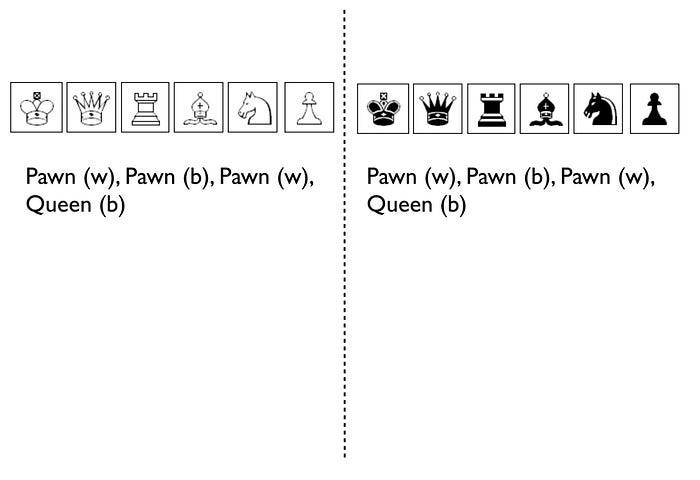
Now both players can see what the other has pressed, white started with Pawn (w), black countered with Pawn (b) and so on. The game will continue until a draw is determined or someone has won. Neither player is aware of the concept of a board or that each of the characters may represent one of many pieces (i.e. there are eight Pawns). However, this lack of awareness won’t stop people playing and others collecting numerous sequences from different games. With enough games, people will start to discover “magic sequences” of success. If you press Knight, I should counter with Pawn, Pawn, and Bishop!
Gurus will write books on the “Secrets of the Queen” and people will copy the moves of successful players. People will convince themselves that they know what they’d doing and the importance of action — you can’t win without pressing a character! All sorts of superstition will develop.
Now imagine you’re playing against someone who can see something truly remarkable — the board. In this game, you will move Pawn(w), the opponent will counter Pawn (b), you will move again Pawn(w), they will counter Queen(b) and you will have lost. I’ve shown this in the figure below.
Figure 5 — Chess World vs The Board
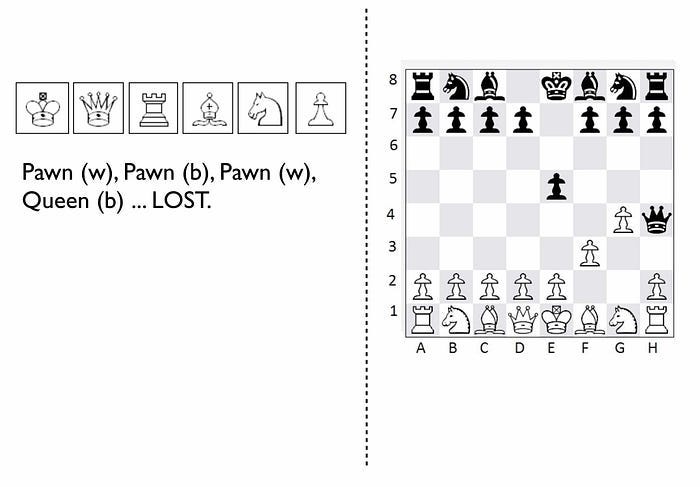
Remember, you have no idea that the board exists and you can only see what is on the left hand side i.e. the characters you press and the sequence. You will almost certainly be shocked by the speed at which you have lost the game. You’ll probably scribble down their sequence as some sort of magic sequence for you to re-use. However, every time you play this opponent, no matter what you do, no matter how you copy them, you will lose and lose quickly.
You’ll probably start to question whether there is some other factor to success? Maybe it’s the speed at which they press the characters? Maybe they are a happy person and somehow culture and disposition impacts the game? Maybe it’s what they had for lunch? To make things worse, the board provides the opponent with a learning mechanism to discover repeatable forms of gameplay i.e. fool’s mate. Against such a player, you are doomed to lose in the absence of lucky breaks for yourself and some sort of calamity for the opponent.
For a young CEO this started to feel rather disturbing. I had the sneaking suspicion that I was the player pressing the buttons without seeing the board. We were doing fine for now but what happened if we came up against such a competitor? If they could see the board then I was toast. I needed some way to determine just how bad my situational awareness was.”
he goes on to describe even more of the impact that this kind of intelligence can have on our lives, businesses and decisions, but i’ll cut it short here.
while wardley mapping is certainly deep and useful, it’s still just a framework/set of tools you can use to do medium/low-fidelity systems mapping. for a system as wide and deep as the internet or the sum of humanity’s knowledge, it doesn’t stand up to the task.
integral theory does the best job i’ve seen at it, by encapsulating all of the world’s knowledge onto its AQAL framework, considering multiple dimensions of knowledge and perspectives.
but before i dive into it,
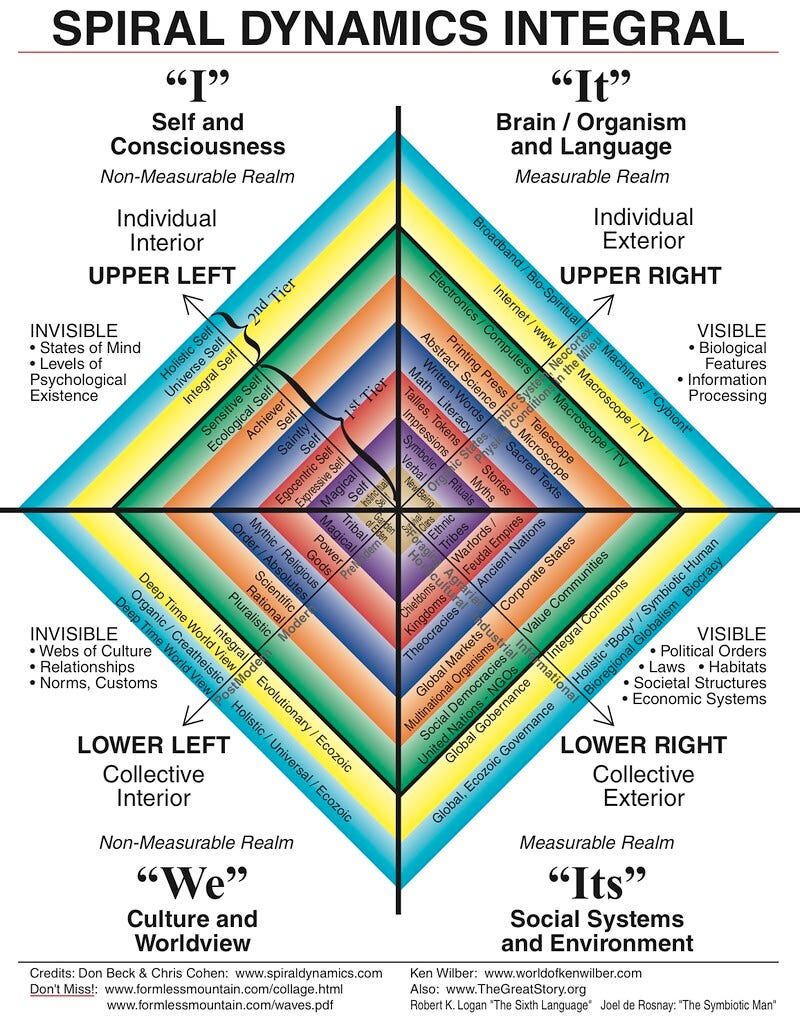
jeff provides a good overview here with his list of some of the best/most interesting knowledge maps he found on the web.
nadia also shares a useful categorization of maps that she calls skeumorphic, schematic, matrix, “chinese menu”, word cloud and “type of guy” maps, on her participation on the stoa.
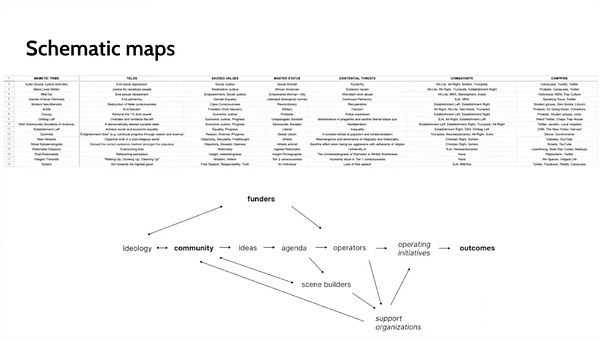
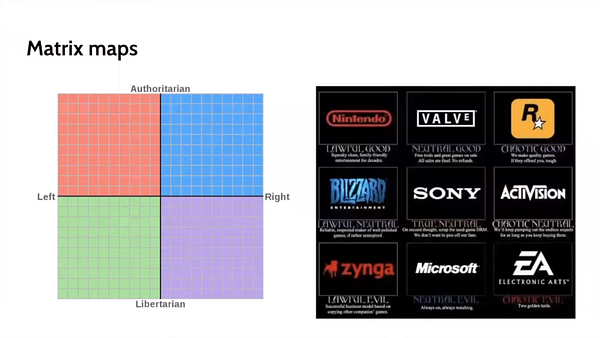

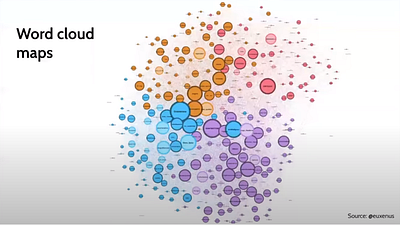
if you’re interested, i recommend checking out the full thing when you have some time:
another simple classification framework i use for it is: concept maps, topical maps & reference maps.
examples:
concept maps:
(a.k.a. concept illustration
topical maps:
(maps that serve to illustrate your thinking, topics, questions and relationships on a topic you’re exploring)
reference maps:
(maps that categorize/give visibility to people / organizations / communities in a field)
i’m very biased, as i’m someone who has been looking for such maps and tools for making them for years, and haven’t found any of them to be particularly good/useful yet. (+ feeling discouraged/frustrated by the amount of work it’d take to come up with a solution by myself)
azl’s thread (below) represent well my perspective on the topic too. we’re still rudimentary on this subject.
nonetheless, there’s been some decent applications, such as envisioning’s techdetector radar and some promising possibilities for the future, like the ones presented at the mapsmap hackathon and a few AI initiatives like omniscience, atlas, origintrail, re:collect, elicit, the graph, but some of them still notoriously hard to implement/use/customize.
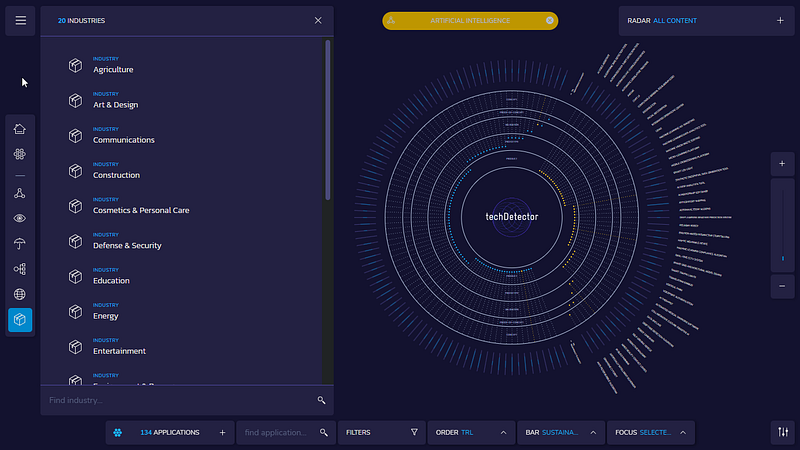
envisioning’s techdetector radar
yet, it’s not alive, dynamic, in a socio-technological, shared reality sense. there’s no integral database or interface for navigating the world’s knowledge, in spite of some proofs of concept here and there.

AQAL dashboard concept applied to the individual.
like i was saying before, the access to this knowledge remains a big challenge, leading many independent initiatives to tackle parts of it. a few relevant examples being: embedding the internet, publishing (most) text as hypertext, and the burst of AI tools scraping, indexing, filtering and curating the web on our behalf.
recently i’ve been noticing a trend towards reinforcing the closed design of the current big tech/social media platforms. with elon musk’s acquisition of twitter, many people chose to spend more time on web 2.5 platforms such as mastodon and bluesky, and there are some more concerning policies happening such as the changes to twitter and reddit’s changes in API access, leading to the deactivation of many tools and 3rd-party clients.
i see this is both a detriment to our use of the existing systems to make sense of information, as well as a push towards adopting better systems, closer to agent-centric designs.
on “the war on sensemaking I”, daniel poses the threat of weaponizing our exponentially developing technological systems to scale information warfare. the change needs to happen both at an individual level — sharing truthfully, building trust networks, committing to being “islands of coherence”, i.e. not propagating misinformation and not withholding information — and also at a systems design level. our capitalist, self-interest-based economy drives such predatory behavior, so changes to the incentive mechanisms behind sharing information and monetizing it are long overdue.
the biggest contender i discovered to transforming this reality on a systems-level is holochain, a biomimetically-designed system for enabling holonic data management & collaboration via plant-like communication protocols.
proposition of currencies as “current-sees”, i.e. information flows to enable “deep wealth” — wealth in its multiple dimensions.
as it’s a highly technical project that hasn’t focused much on promotion, only a some people in this community (and in the world in general) are aware/supportive of their development.
2) digital gardens
digital gardening simply put_,_ is the practice of building your own space on the web, sharing and tending to your notes.
people categorize their notes and tend to their public gardens around certain growth stages, usually: seedling, budding and evergreen notes_._
digital gardens are a reality for some time among the PKM (personal knowledge management) circles. maggie appleton is an amazing digital anthropologist, designer & illustrator who wrote about a brief history of this movement and curated a list of well-known/engaged digital gardeners.
as a concept/practice, i find that digital gardens are already very valuable and inspiring. i highly recommend people to check out different gardens to get a feel for their value/potential.
some of my suggestions are: maggie appleton, nikita voloboev, azlen elza, alex komoroske, tom critchlow, gordon brander, gwern, bianca aguilar, scaling synthesis.
the PKM/TfT (tools for thought) communities have grown a lot with the evolution and adoption of notion into mainstream use (largely driven by productivity youtubers such as matt d’avela, , through the launch of roam research in 2016 as the first modern hyperlinked/graph-based note-taking tool (giving rise to many other popular tools today such as obsidian, remnote, logseq and tana) and the popularization of tiago forte’s BASB (building a second brain) methodology in the recent years.
from my recent experience at an agroecological site, i noticed what’s missing on this digital movement, from an ecological/regenerative perspective is a deeper awareness of where all of this info-vegetation is planted, in relationship with what/whom.
there are many people interested in attaining this deeper awareness, in a few different ways. usually through the lenses of open knowledge, interoperability, blockchain and hyperlinked docs (all elements of the generations-old dream of the semantic web).
but this is still an underdeveloped topic, with lots of potential for creation/innovation.
3) online browsing & curation mechanisms
the layers & territories of the web:

distinctions/neologisms proposed by venkatesh rao, built upon by maggie appleton.
i find this way of seeing the web very clarifying, as well as telling of the problems of closed-source/extractivist/siloed data applications.
there’s even a great deeper analysis + futures-oriented design/prototypes proposed by trust — moving castles, which brings a greater level of intentionality and ownership over our media platforms and their designs.
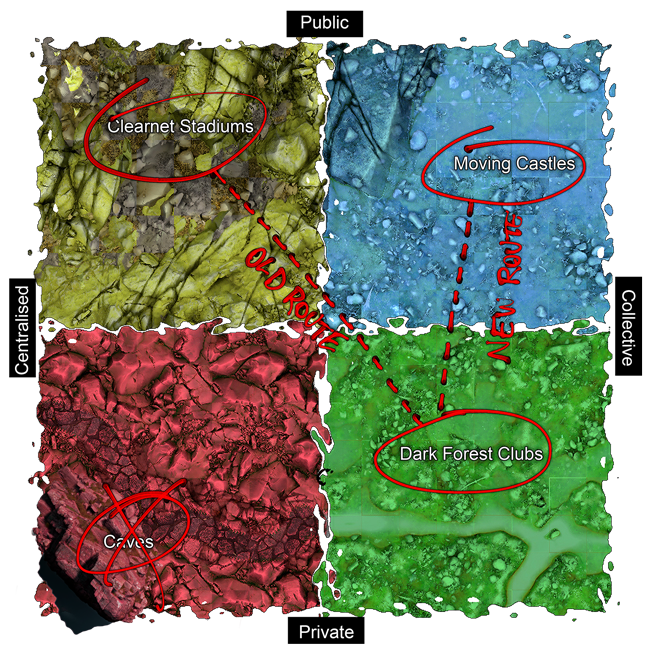
map from trust’s moving castles article. inspired by the eghbal model of open-source communities, “working in public: the making and maintenance of open source software”, nadia eghbal (2020).
x) sublime (ex-startupy.world)
sari is the founder of one of the initiatives i mentioned (sublime), and a master of finding/crafting powerful insights on information curation and the web.
especially relevant as AI floods the content/information sphere and the impact of its algorithms become more important/present in our lives.
a few of them:
1)
2)
“The world doesn’t need another note-taking or bookmarking tool but it does need more spaces that feel sublime — calm, intellectually and creatively nourishing, meditative, full of wonder and possibility.” — written in an email
4)
4) types of networks, digital/physical spaces, and information quality, segmented by platform
throughout my own experience surfing the web and being disoriented by the amount of lifeless SEO-optimized content, propaganda, clickbait and formulaic copywriting, i came to identify few different categories of knowledge i was interested in and the best platforms i found for discovering/curating it.
they are:
concepts/fields of study — wikipedia + side portal
scientific papers — open knowledge maps
thoughts/new references/industry updates — twitter (twitter lists + tweetdeck [now paid] + twemex) + blogs/newsletters
(RSS feeds at their current state require a lot of work to set up in a way that works well. since telegram is a platform i use every day, one alternative i’ve found is using telegram’s gmail bot, so it’s easier/better to skim through emails and figure out which ones are really worth your time without having to click to open each of them)
community-curated insights/highlights — startupy (soon to be sublime)
organizations — golden
communities — specialized catalogs (such as trove, life itself, gaianet) & mapping initiatives (such as map of reddit, youtube atlas, map of github, twitter communities, map of twitch…)
with the new AI wave, there are some interesting podcast/youtube transcripts & highlighting tools popping up as well — snipd and glasp being the ones i tried/enjoyed the most (but still not quite there).
also, one of the best applications of AI in this direction i’ve seen is stephen reid’s individual’s knowledgegraphs.
the information types i still haven’t found great resources on are:
(linking some “ok” references i found)
-
books - audiobooks, summaries, fine-tuned LLMs.
-
search data (from both traditional search engines and AI-powered ones)
after researching/testing these plus around 200 other tools/platforms (mostly logged here), i arrived at the core of what interested me in this space.
- user-generated VR worlds / mind palaces. (scaling connection)
- AI agents / decentralized knowledge/information curation. (increasing optionality/serendipity)
- interfaces enabling better individual & collective intelligence. (improving sensemaking/decision-making)
5) proto-designs i’ve been working on
in december 2022, obsidian has launched the “canvas” option, which allows you to spatially navigate your (hyperlinked) notes as well as interactive web pages.
it’s great, but still can’t handle some things such as cookies (for extended browsing sessions) and becomes slow with too many tabs/pages open.
softspace is also very close to releasing this possibility in AR/VR.
by experimenting with these tools, i felt closer than ever to solving a need i’ve felt for a long time: a personal algorithm & omnichannel curation space.
i.e. a space that aggregates all of your (online and offline) knowledge sources, in a private, personalized and context-relevant way.
instead of making something from scratch (which would be beyond my individual abilities), i arrived at some basic data formats and their respective best (existing) management tools today:
pages (bookmarks) — raindrop
text (notes/highlights) — obsidian / telegram
images — eagle
videos — youtube / pockettube
audio — still haven’t found a good one. i really like splice’s interface as a reference.
personal metrics — synapsis (coming soon, being developed by my friend ísis), followed by some ok tools — rize, rescuetime, toggl.
we’re at a point now in which AI-driven design, prototyping and software development is becoming viable. as i arrived at this as the primary “tech stack”, now it’s a matter of plugging webhooks.
all of the tools i mentioned so far with the exception of synapsis intend to make the best use of what digital tools/infrastructure exists today, not reinvent it in a fundamentally different way (distributed, private, regenerative, etc).
if we look beyond the speculative/hyperfinancialized sphere of web3, the dream of the semantic web remains alive and closer than ever, as we’re developing new infrastructure to host and scale it.
the most promising projects i’ve discovered on this front are:
-
but you have to speak 8 levels of nerd in order to "get" most of them (i spent 1 whole year living and breathing SEEDS to really get it, at deeper levels).